| Source | Pose | Animation |
Image-to-video(I2V) generation aims to create a video sequence from a single image, which requires high temporal coherence and visual fidelity with the source image. However, existing approaches suffer from character appearance inconsistency and poor preservation of fine details. Moreover, they require a large amount of video data for training, which can be computationally demanding. To address these limitations, we propose PoseAnimate, a novel zero-shot I2V framework for character animation. PoseAnimate contains three key components: 1) Pose-Aware Control Module (PACM) incorporates diverse pose signals into conditional embeddings, to preserve character-independent content and maintain precise alignment of actions. 2) Dual Consistency Attention Module (DCAM) enhances temporal consistency, and retains character identity and intricate background details. 3) Mask-Guided Decoupling Module (MGDM) refines distinct feature perception, improving animation fidelity by decoupling the character and background. We also propose a Pose Alignment Transition Algorithm (PATA) to ensure smooth action transition. Extensive experiment results demonstrate that our approach outperforms the state-of-the-art training-based methods in terms of character consistency and detail fidelity. Moreover, it maintains a high level of temporal coherence throughout the generated animations.
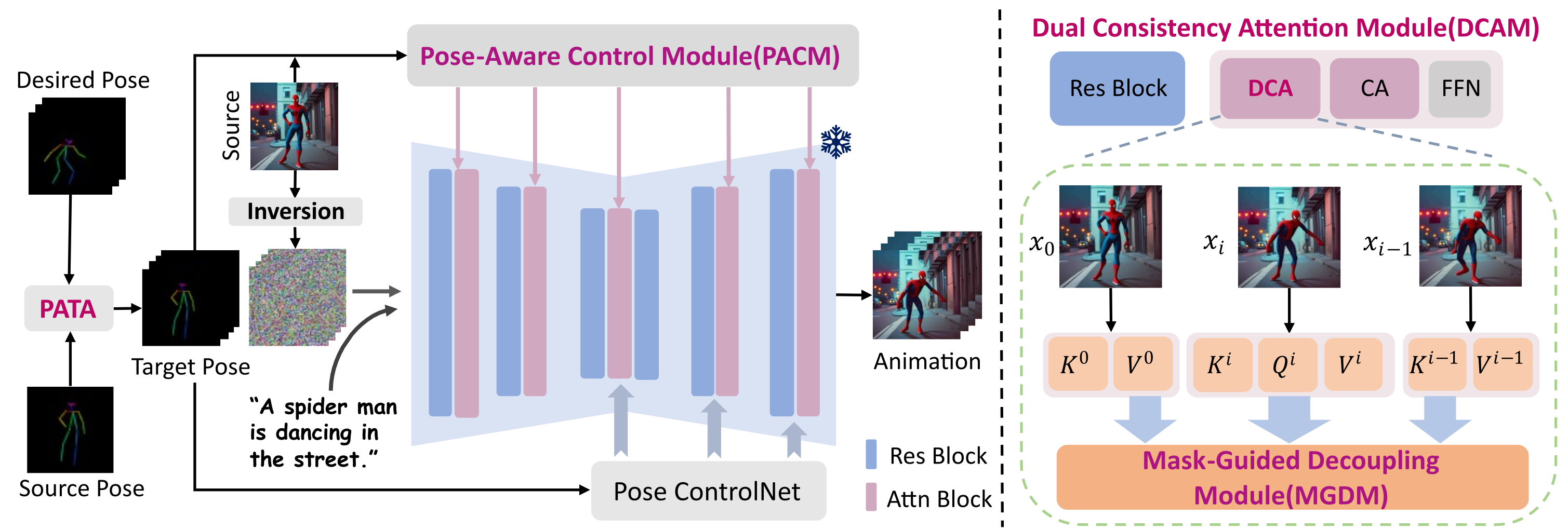
Overview of PoseAnimate. The pipeline is on the left, we first utilize the Pose Alignment Transition Algorithm(PATA) to align the desired pose with a smooth transition to the target pose. We utilize the inversion noise of the source image as the starting point for generation. The optimized pose-aware embedding of PACM, in Sec.3.2, serves as the unconditional embedding for input. The right side is the illustration of DCAM in Sec.3.3. The attention block in this module consists of Dual Consistency Attention (DCA), Cross Attention (CA), and Feed-Forward Networks (FFN). Within DCA, we integrate MGDM to independently perform inter-frame attention fusion for the character and background, which further enhance the fidelity of fine-grained details.